Auto-merging Retrieval for Context Efficiency¶
by Grayson Adkins, updated April 12, 2024
This notebook demonstrates auto-merging retrieval, an advanced RAG technique for improving retrieval performance.
![]()
Attribution¶
This notebook is largely based on the DeepLearning.AI course Building and Evaluating Advanced RAG Applications by Jerry Liu of LlamaIndex and Anupam Datta of CMU and TrueEra.
However, in this implementation I make a few changes to the original course material:
- Fixed breaking changes introduced by LlamaIndex v0.10.0
- Migrated
ServiceContextconfiguration to newSettingsobject - Swapped out the existing example data with the much larger collection of Paul Graham's essays, which includes over 500K words. This larger corpus makes the retrieval process even more challenging and gives us more room for improving retrieval with this advanced RAG technique.
Why should you read this notebook?¶
You want to:
- Learn how to improve the generated reponses in your basic RAG pipeline
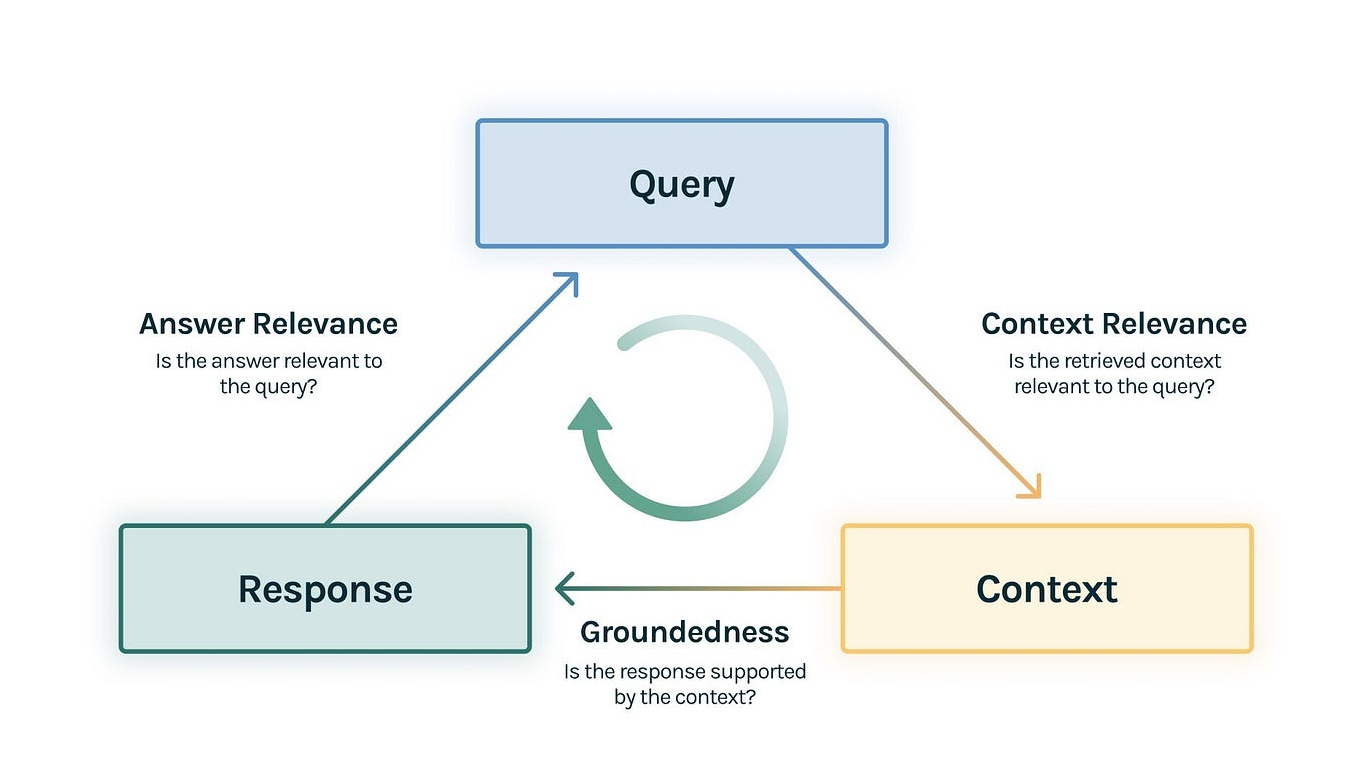
- Have a way to evaluate the relevance of both the retrieved context and generated reponses
- Quantify and visualize experiments and compare them to other advanced RAG techniques as you iterate on your RAG pipeline
Motivation & Main Idea¶
We want to improve upon basic (naive) RAG by improving the context provided to the LLM to achieve better generated responses.
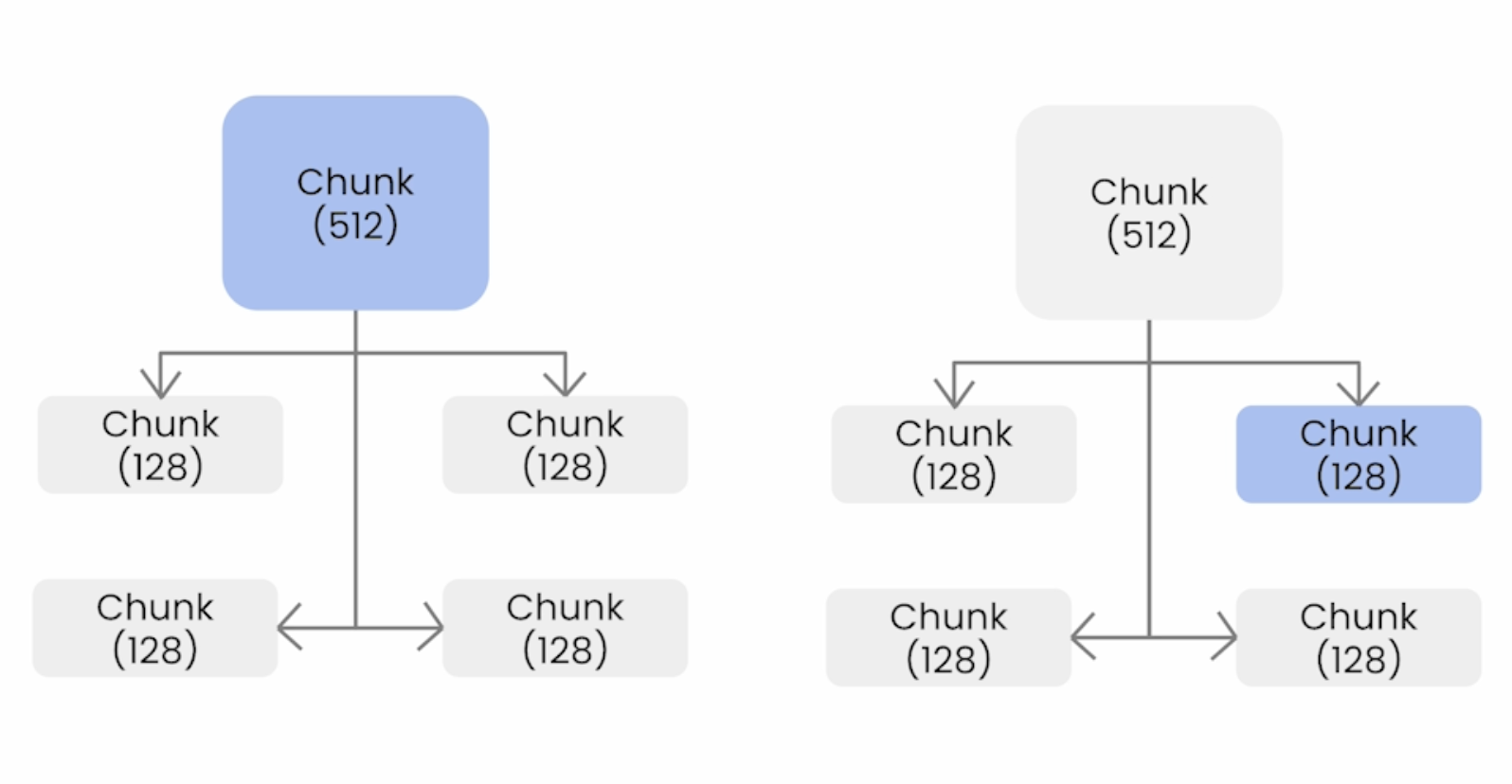
With auto-merging retrieval, we construct a hierarchy of larger parent nodes with smaller child nodes that reference the parent node, i.e. a parent node consists of all the sentences of its child nodes. At retrieval time, if the parent node has a majority of it's child nodes retrieved, then the child nodes are replace with the parent node. This process ensures that even if we don't perfectly retrieval all relevant child nodes, we will still include this information in the context by using the parent node.
Summary of Results¶
I find auto-merging retrieval to be hit-and-miss in terms of whether it yields better quality answers, but it provides a significant cost savings through more efficient token utilization.
In my first round of tests, I observed Answer Relevance improve by 10.6% and Groundedness improve by 18.2%, while Context Relevance decreased by 13.4%. However, in subsequent tests, I observed degraded performance across all three metrics.
Yet, when Jerry Liu demoed this technique in his DeepLearning.AI course, he showed significant improvement not just over basic RAG, but also sentence window retrieval; whereas I've observed better performance in the latter. This discrepency likely has to do with my data and set of eval questions, though, I can't point to anything in particular.
On a positive note, compared to basic RAG (using LlamaIndex's Direct Query Engine), I observed a 78.4% decrease in total tokens, while maintaining roughly comparable answer quality. This reduction resulted in a 3x cost savings. Intuitively, we can assume the auto-merging retrieval technique is providing more granular, succinct, and relevant context than the basic RAG pipeline.
Overall I would not exclusively rely on auto-merging retrieval, but it would be interesting to suppliment with other advanced techniques.